Skip to content
Release Notes
Release notes
v1.4 [20Q1]
1.4.1:
tensorforce reintegrated (due to an incompatibility between tfagents and
tensorforce, tensorforce must be explicitely activated
by a call to agents.activate_tensorforce() )
upgrade to tfagents 0.3, tensorflow 2.0.1
kwargs for register_with_gym
1.4.0: agent saving & loading (see intro
Saving & loading a trained policy );
lineworld as test environment included
v1.3 [19Q4]
1.3.1: agent.score substituted by agent.evalute;
1.3.0: migration to tensorflow 2.0;
support for tensorforce and keras-rl suspended until support for tf 2.0 is available
v1.2 [19Q3]
1.2.2: fix for CemAgent and SacAgent default backend registration
1.2.1: SacAgent for tfagents preview; notebook on 'Agent logging, seeding and jupyter output cells'
1.2.0: Agent.score
v1.1 [19Q3]
1.1.23: CemAgent for keras-rl backend; DqnAgent, RandomAgent for tensorforce
1.1.22: DuelingDqnAgent, DoubleDqnAgent with keras-rl backend
1.1.21: keras-rl backend (dqn)
1.1.20: #54 logging in jupyter notebook solved, doc updates
1.1.19:
jupyter plotting performance improved
plot.ToMovie with support for animated gifs
1.1.18: tensorforce backend (ppo, reinforce)
1.1.11:
plot.StepRewards, plot.Actions
default_plots parameter (instead of default_callbacks)
v1.0.1 [19Q3]
api based on pluggable backends and callbacks (for plotting, logging, training durations)
backend: tf-agents, default
algorithms: dqn, ppo, random
plots: State, Loss (including actor-/critic loss), Steps, Rewards
support for creating a mp4 movie (plot.ToMovie)
v0.1 [19Q2]
prototype implementation / proof of concept
hard-wired support for Ppo, Reinforce, Dqn on tf-agents
hard-wired plots for loss, sum-of-rewards, steps and state rendering
hard-wired mp4 rendering
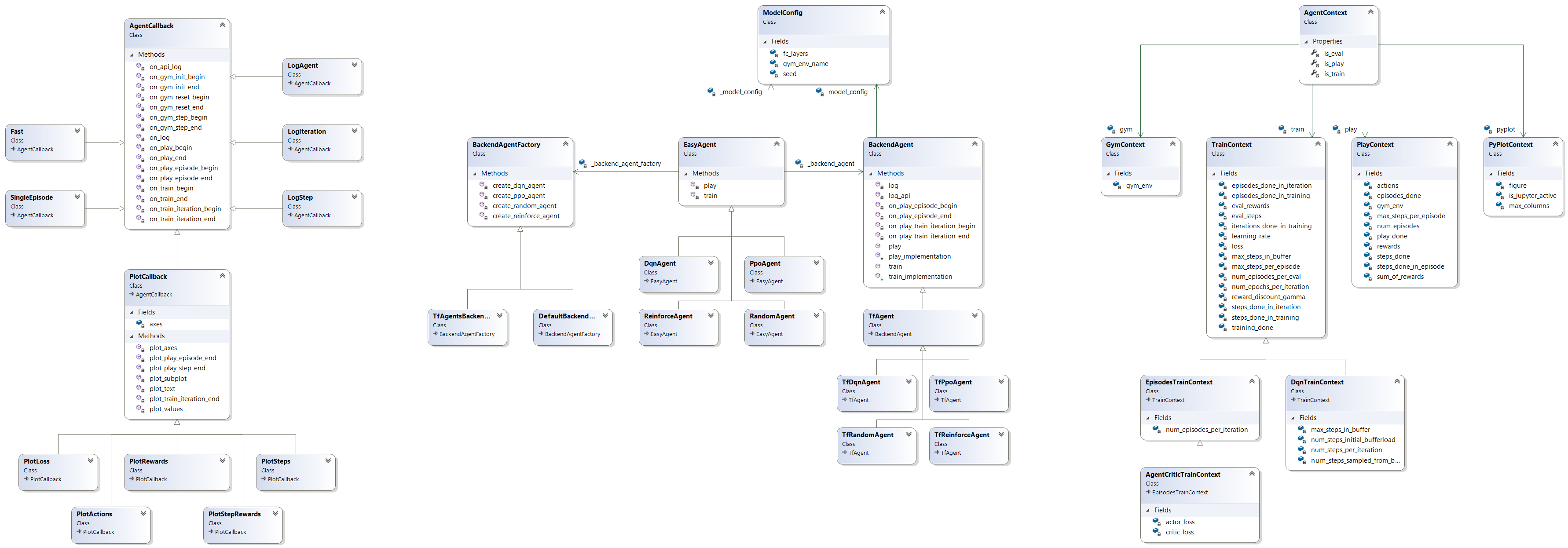
Design guidelines
separate "public api" from concrete implementation using a frontend / backend architecture
(inspired by scikit learn, matplotlib, keras)
pluggable backends
extensible through callbacks (inspired by keras). separate callback types for training, evaluation and monitoring
pre-configurable, algorithm specific train & play loops
Class diagram